O projekcie
Projekt powstał w celu nauki samodzielnego projektowania i utrzymania infrastruktury. Infrastruktura opiera się na ekosystemie Proxmox (Virtual Environment oraz Backup Server), jest ona używana jako zaplecze dla własnych projektów, usług self-hosted i nauki administracji systemami. Środowisko pozwala na eksperymenty z kontenerami, wirtualnymi maszynami i różnymi aplikacjami użytkowymi, przy jednoczesnym zachowaniu kontroli nad bezpieczeństwem i dostępem do usług. Jest ono używane głównie przeze mnie, okazjonalnie przez kilku użytkowników.
Sprzęt

- Router TP-Link ER605 v2 pełni funkcję bramy sieciowej.
- Switch niezarządzalny TP-Link 5p LS1005G.
- Główny serwer to Lenovo ThinkCentre M720q Tiny, wyposażony w procesor i5-8500T, 32 GB RAM oraz dyski 500 GB NVMe i 1 TB SATA SSD. Wybrałem go ze względu na niski pobór mocy (~12,5W w idle) przy stosunkowo wysokiej wydajności, co pozwala na ciągłą pracę bez znacznych kosztów energii.
- Serwer na backupy to Lenovo ThinkCentre M910q Tiny, wyposażony w procesor i3-7100T, 16 GB RAM oraz dyski 256 GB NVMe i 500 GB SATA SSD.
- Customowy stojak, wydrukowany w 3D.
Architektura środowiska
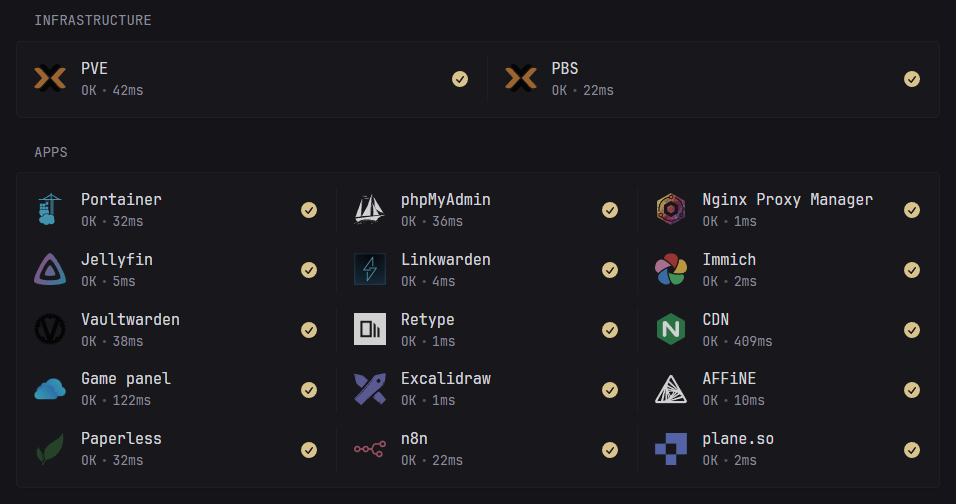 Platformą wirtualizacji jest Proxmox Virtual Environment.
Usługi są hostowane w kontenerach LXC lub Docker oraz VM.
Kontenery LXC są używane ze względu na niskie wykorzystanie zasobów. VM są używane tam, gdzie wymagana jest pełna izolacja.
Platformą wirtualizacji jest Proxmox Virtual Environment.
Usługi są hostowane w kontenerach LXC lub Docker oraz VM.
Kontenery LXC są używane ze względu na niskie wykorzystanie zasobów. VM są używane tam, gdzie wymagana jest pełna izolacja.
Sieć
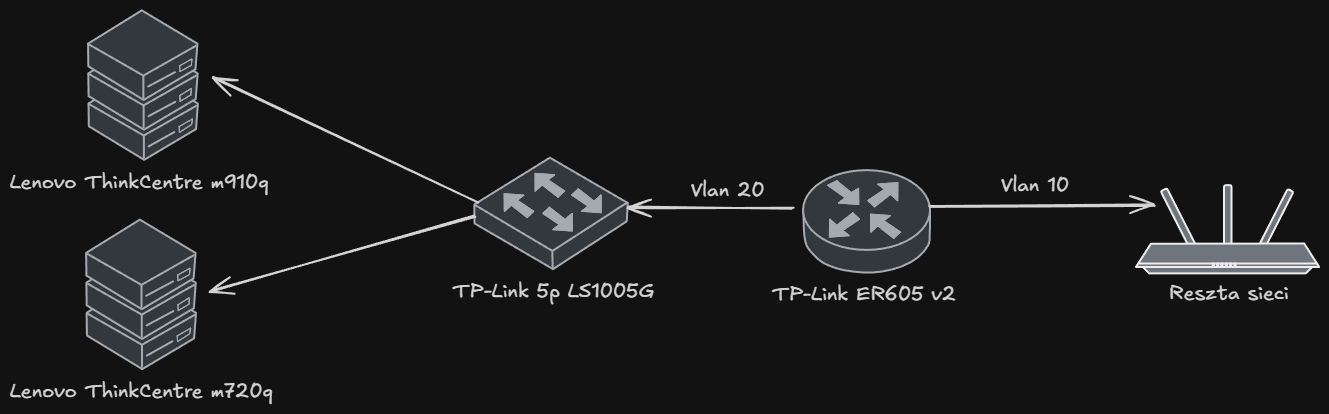 Sieć jest podzielona logicznie na VLAN-y, które separują ruch użytkowy od serwerowego.
Ruch między VLAN-ami nie jest filtrowany na poziomie routera, ze względu na ograniczenia softwarowe.
Kontrola dostępu jest realizowana na poziomie hostów (PVE firewall), gdzie wybrane maszyny mają restrykcyjne reguły komunikacji.
Sieć jest podzielona logicznie na VLAN-y, które separują ruch użytkowy od serwerowego.
Ruch między VLAN-ami nie jest filtrowany na poziomie routera, ze względu na ograniczenia softwarowe.
Kontrola dostępu jest realizowana na poziomie hostów (PVE firewall), gdzie wybrane maszyny mają restrykcyjne reguły komunikacji.
Przykładowa konfiguracja firewalla w PVE, dla publicznie wystawionej usługi:
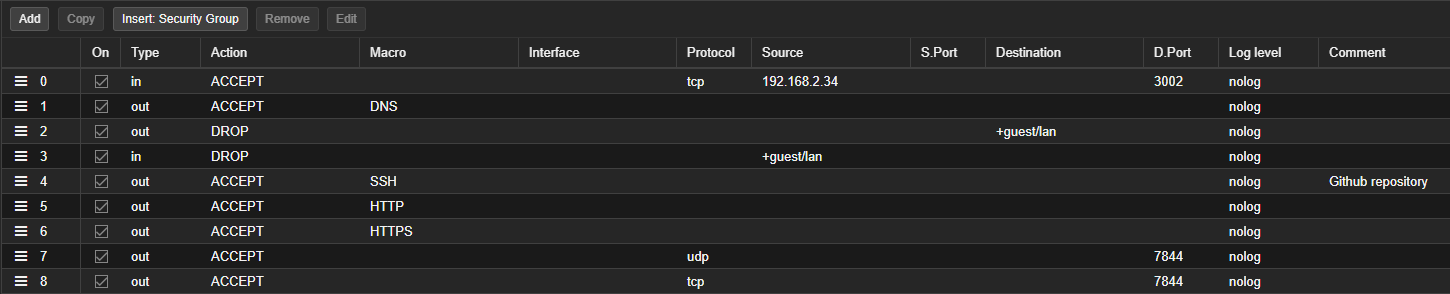 Dodatkowo
Dodatkowo Input oraz Output Policy jest ustawione na Drop.
Eksperymentowałem z wdrożeniem Omada Controller jako VM w Proxmoxie, aby odblokować pełne funkcje filtracji ruchu. Napotkałem jednak problem - proces adaptacji routera wymusza reset ustawień do domyślnych, co przy adresacji mojego homelabu (192.168.2.0/24) powoduje utratę łączności z kontrolerem.
GitOps dla usług Dockerowych
 W poszukiwaniu sposobu na łatwe aktualizacje wszystkich usług w Dockerze, zaimplementowałem w moim homelabie workflow na wzór klasycznego GitOps.
W poszukiwaniu sposobu na łatwe aktualizacje wszystkich usług w Dockerze, zaimplementowałem w moim homelabie workflow na wzór klasycznego GitOps.
Workflow aktualizacji stacka wygląda następująco:
- Wychodzi nowa wersja obrazu Dockera.
- Renovate otwiera pull request.
- Pull request jest przeglądany i merge'owany przeze mnie.
- Portainer robi polling repo co 2 minuty:
- Jeśli wykryje zmiany, pobiera najnowsze
docker-compose.ymlz repozytorium. - Następnie wykonywany jest redeployment całego stacka.
- Jeśli wykryje zmiany, pobiera najnowsze
Portainer działa w trybie polling, z powodu przewagi bezpieczeństwa tego rozwiązania nad webhookiem, ponieważ nie wymaga publicznego wystawiania endpointu.
W powyższej konfiguracji cały proces wykrywania nowych wersji i późniejszego deploymentu jest w pełni automatyczny.
Moim zadaniem przy aktualizacji jest jedynie sprawdzenie i zmerge'owanie pull requestu.
W przypadku, gdy z jakiegoś powodu usługa nie uruchamia się na nowej wersji, mogę łatwo przywrócić stary obraz, robiąc revert pull request'a.
Początkowo wszystkie docker-compose.yml usług były w monorepo, ale powodowało to taki problem, że za każdym razem, gdy repozytorium zostało zaktualizowane, portainer robił redeployment wszystkich istniejących stacków, które korzystały z tamtego repozytorium.
Dlatego teraz każda usługa, która jest hostowana w Dockerze, ma własne repozytorium na GitHubie.
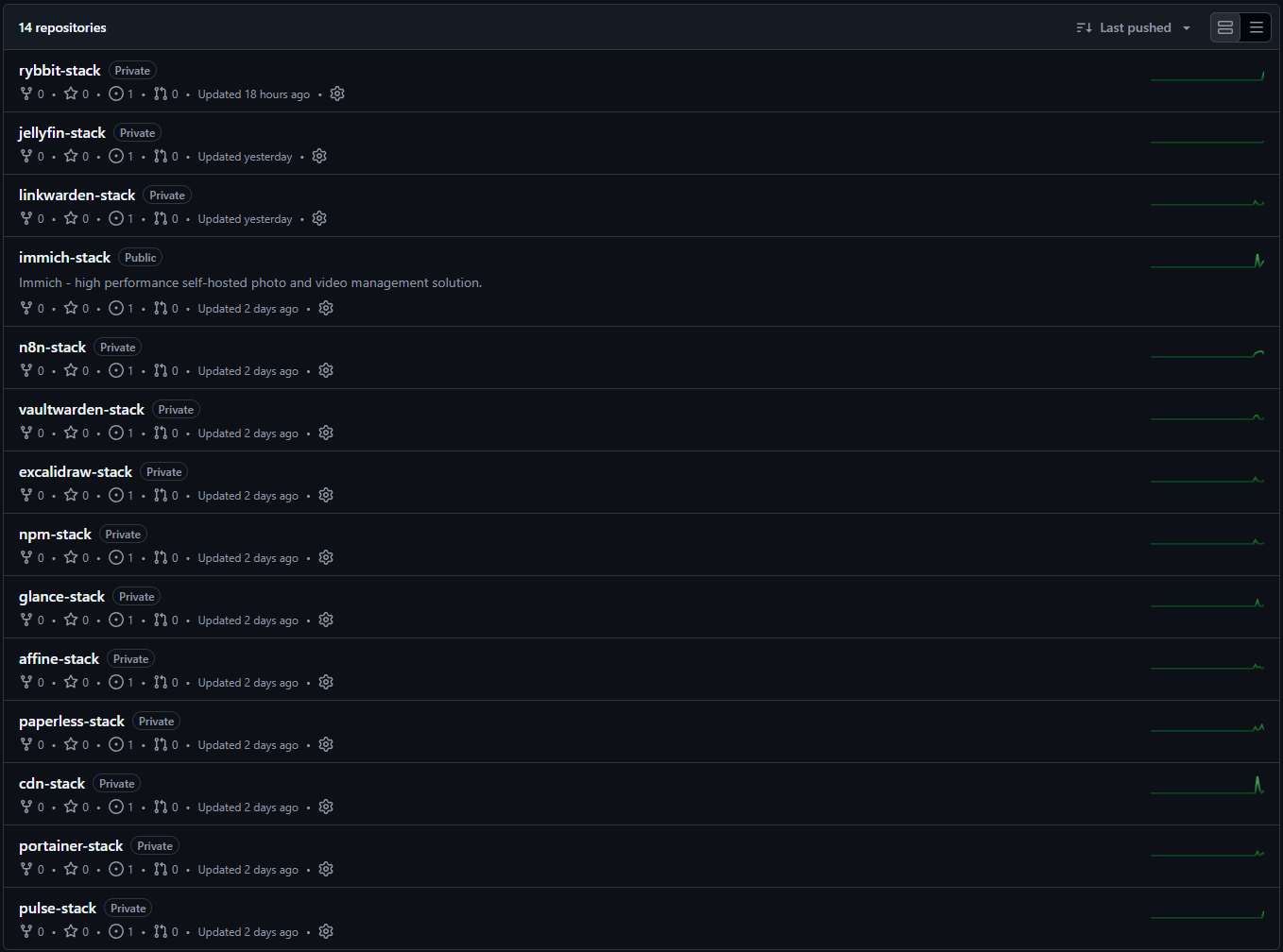
Wybrane repozytoria z powyższych są open source i są dostępne na GitHubie.
W repozytoriach przechowuję jedynie pliki .env.example. Same sekrety i zmienne środowiskowe konfiguruję bezpośrednio wewnątrz Portainera podczas pierwszego wdrożenia stacka. Dzięki temu wrażliwe dane nie wyciekają do historii commitów na GitHubie.
Po zautomatyzowaniu aktualizacji, stacki są znacznie częściej aktualizowane, przez co są pobierane nowe obrazy. Stworzyło to nowy problem lokalnego przechowywania dużej ilości nieużywanych obrazów, co niepotrzebnie zajmowało przestrzeń dyskową.
W celu rozwiązania tego problemu, wdrożyłem zadanie cron (docker image prune -af), które codziennie usuwa nieużywane obrazy.
Dostęp do usług
Tylko wybrane usługi są dostępne z internetu i w przypadku stron internetowych są wystawione przez tunel cloudflare.
Gdy nie ma prostej możliwości, by daną usługę wystawić przez tunel i jest konieczność otworzenia portu, nie udostępniam publicznego adresu IP mojego routera,
a zamiast tego korzystam z zewnętrznego dostawcy reverse-proxy w celu zminimalizowania skuteczności ataków typu DoS/DDoS (Denial of Service/Distributed Denial of Service).
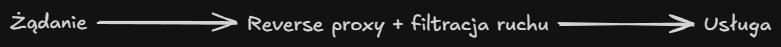
Dostęp do prywatnych usług, których nie chcę bezpośrednio wystawiać przez internet, realizuję za pomocą sieci VPN Tailscale.
Dzięki temu mam do nich dostęp z dowolnej części świata, bez ryzykowania ich bezpieczeństwa.
W celu jeszcze większego bezpieczeństwa ograniczyłem dostęp z sieci VPN tylko do segmentu VLAN przeznaczonego dla homelabu.


Certyfikaty SSL
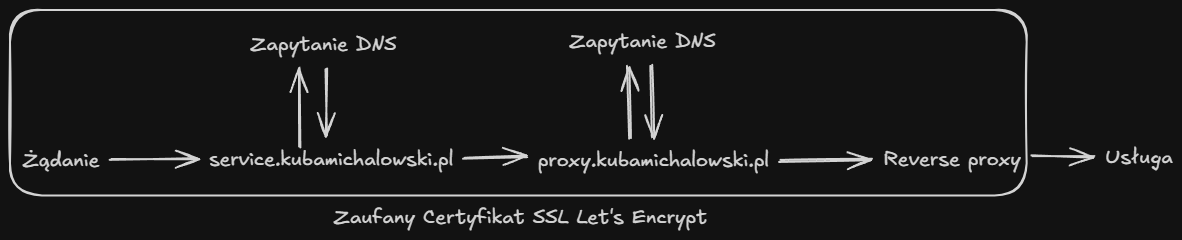
Każda usługa w moim homelabie ma przydzieloną własną subdomenę, wraz z certyfikatem SSL Let's Encrypt.
Certyfikaty SSL są generowane z użyciem DNS challenge, dzięki temu, usługi te nie muszą być dostępne z internetu i każda usługa może mieć zaufany certyfikat SSL.
Certyfikaty są obsługiwane przez reverse proxy lub bezpośrednio przez daną usługę.
Monitoring
Monitoring zewnętrzny
Usługa BetterStack monitoruje dostępność moich publicznych usług z zewnątrz i wysyła powiadomienia o incydentach.
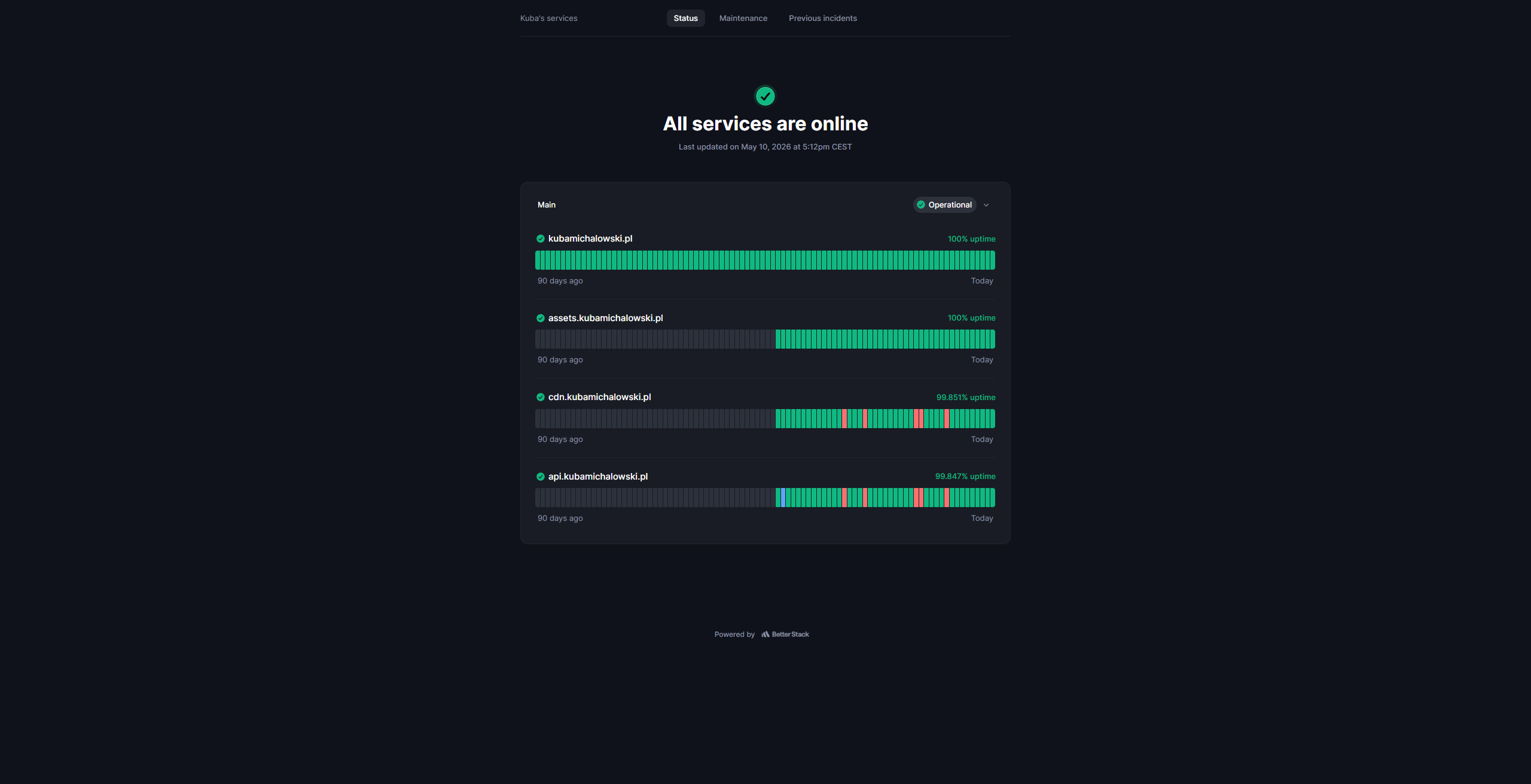
Monitoring lokalny
Do monitorowania hostów, kontenerów i usług wewnątrz sieci początkowo wdrożyłem Pulse, ze względu na jego prostotę.
Jednak rozwiązanie to okazało się mieć wiele wad (między innymi 95% alertów to były false-positivy) i obecnie jestem w trakcie migracji na stack Loki + Prometheus + Grafana.
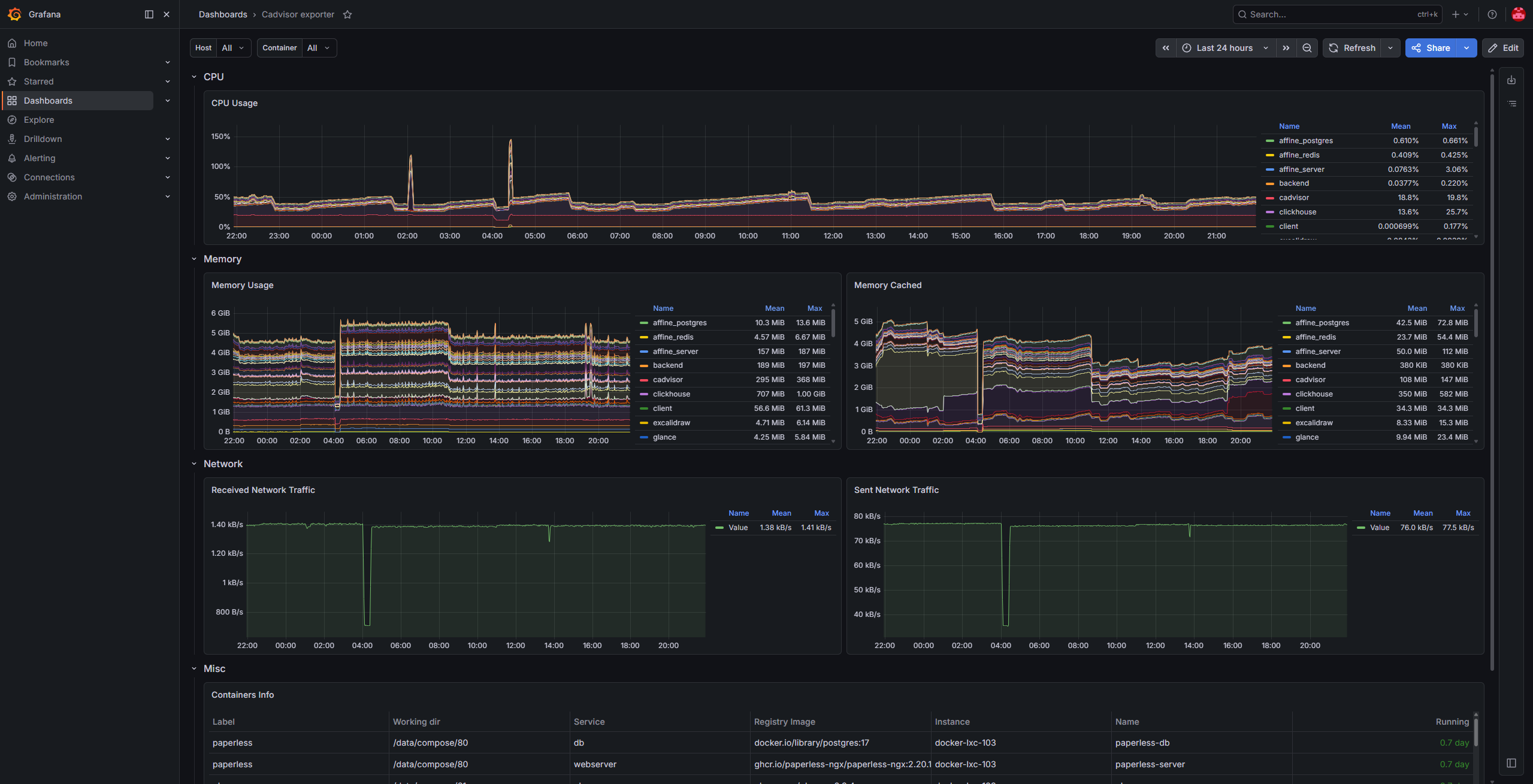
Obecnie mam już wdrożone:
node-exporter: na PVE oraz PBS.cAdvisor: na każdym hoście Docker-a.pve-exporter: pobierający metryki z api PVE.pbs-exporter: pobierający metryki z api PBS.
Infrastruktura e-mail
W celu zapewnienia niezawodnego dostarczania powiadomień systemowych oraz profesjonalnej obsługi wielu adresów e-mail w mojej domenie, wdrożyłem hybrydowy model routingu.
Rozwiązanie to łączy dwie usługi:
-
Cloudflare Email Routing: Obsługuje ruch przychodzący. Pozwala na tworzenie nielimitowanej liczby aliasów, które są automatycznie przekierowywane na moją prywatną skrzynkę.

-
Mailgun: Pełni funkcję serwera SMTP do wysyłki powiadomień z usług działających wewnątrz homelabu.

Dlaczego taka konfiguracja?
Połączenie tych usług rozwiązuje dwa kluczowe problemy:
- Brak kosztów operacyjnych: Wykorzystuję darmowe plany obu usług (m.in. do 3000 wiadomości miesięcznie w Mailgun), co pozwala na profesjonalną obsługę poczty przy zerowym koszcie.
- Prostota rozwiązania: Dzięki tej konfiguracji nie muszę konfigurować i utrzymywać własnego serwera pocztowego, przez co nie muszę się martwić o dostarczalność wiadomości i powiadomienia systemowe nie trafiają do spamu.
Backupy
System backupów w moim homelabie jest obsługiwany przez Proxmox Backup Server.
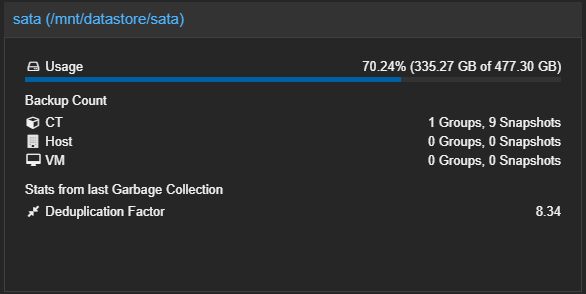
Zaimplementowałem to rozwiązanie, aby rozwiązać problem backupu dużego kontenera LXC z Dockerem (~330 GB).
Dzięki deduplikacji i kopii przyrostowej, 8 dni backupów zajmuje jedynie 335 GB zamiast oczekiwanych ~2.5 TB.
Obecne kopie przyrostowe pozwalają mi na przechowywanie 7 dziennych i 2 tygodniowych kopii zapasowych tego kontenera.
W celu zoptymalizowania zużycia energii, serwer z PBS nie jest uruchomiony w trybie 24/7.
Jest on uruchamiany z użyciem Wake-on-LAN przed backup jobami z użyciem cron'a.
Po wykonaniu backup job'ów hook script sprawdza czy na serwerze z PBS są jeszcze aktywne zadania i jeśli nie to wyłącza serwer.
...output omitted...
INFO: Finished Backup of VM 103 (00:21:22)
INFO: Backup finished at 2026-03-19 03:34:03
INFO: No active tasks, shutting down PBS...
...output omitted...Przed większymi zmianami stosuję również ręczne snapshoty.
Najciekawsze problemy które napotkałem
Pułapka zmiany czasu
W dzień zmiany czasu z CET na CEST, zadanie uruchomienia PBS i backupu, które były zaplanowane na 02:22 i 03:00, zostały uruchomione w tym samym czasie (03:00), co doprowadziło do tego, że PBS nie zdążył się uruchomić przed zadaniem backupu.
INFO: skipping disabled matcher 'default-matcher'
INFO: notified via target `notification`
TASK ERROR: could not activate storage 'pbs': pbs: error fetching datastores - 500 Can't connect to pbs.kubamichalowski.pl:8007 (No route to host)W celu rozwiązania tego problemu i zapewnienia by nigdy więcej się nie powtórzył, przesunąłem wszystkie zadania o godzinę do przodu, przykładowo:
WOL:02:22➞03:22Backup:03:00➞04:00
Dzięki temu mam pewność, że niezależnie od aktualnego czasu, zadania zostaną wykonane.
Zawieszenie karty sieciowej
Zdarzało się, że usługi przestawały odpowiadać na zapytania, a sam serwer nagle przestał odpowiadać na ping, mimo że fizycznie był włączony. Diagnoza wykazała problem ze sterownikiem karty sieciowej:
Dec 11 21:21:54 pve kernel: e1000e 0000:00:1f.6 eno1: Detected Hardware Unit Hang:
TDH <51>
TDT <64>
next_to_use <64>
next_to_clean <50>
buffer_info[next_to_clean]:
time_stamp <1052d01c3>
next_to_watch <51>
jiffies <1052da640>
next_to_watch.status <0>
MAC Status <40080083>
PHY Status <796d>
PHY 1000BASE-T Status <8ff>
PHY Extended Status <3000>
PCI Status <10>Zamiast spędzania godzin na próbie naprawienia tego ręcznie poprzez dostosowywanie ustawień przez ethtool, użyłem gotowego skryptu z community-scripts.org, który automatycznie stworzył usługę systemd, która przy każdym uruchomieniu wyłącza problematyczne funkcje.
...output omitted...
ℹ️ Searching for Intel e1000e and e1000 interfaces...
✔️ Found 1 Intel e1000e/e1000 interfaces
✔️ Selected interface: eno1 (e1000e)
ℹ️ Creating systemd service for interface: eno1 (e1000e)...
✔️ Service for eno1 (e1000e) created and enabled!
ℹ️ Service: disable-nic-offload-eno1.service...
ℹ️ Status: Active...
ℹ️ Start on boot: Enabled...
✔️ Intel e1000e/e1000 optimization complete for 1 interface(s)!
ℹ️ Verification commands:...
ethtool -k eno1 # Check offloading status
systemctl status disable-nic-offload-eno1.service # Check service statusPo wdrożeniu poprawki zweryfikowałem status funkcji offloadingu:
root@pve:~# ethtool -k eno1
Features for eno1:
rx-checksumming: off
tx-checksumming: off
tcp-segmentation-offload: off
generic-segmentation-offload: off
generic-receive-offload: off
rx-vlan-offload: off
tx-vlan-offload: off
...output omitted...Czego nauczył mnie ten homelab
- Automatyzacja to oszczędność czasu - dzięki GitOps, utrzymanie najnowszych wersji ponad 50 kontenerów zajmuje mi teraz sekundy (merge PR), zamiast kilkunastu minut ręcznego sprawdzania wersji.
- Optymalizacja kosztów - efektywne dobieranie sprzętu do hostowania różnych usług przy zachowaniu niskiego poboru mocy.
- Efektywny backup - PBS udowodnił, że deduplikacja danych i kopia przyrostowa to podstawa przy ograniczonych zasobach dyskowych.
Kierunek rozwoju
Poniższa lista stanowi backlog planowanych usprawnień, realizowanych w zależności od priorytetów i dostępnego czasu:
- Dodanie lokalnego serwera
Gitjako mirror dlaGitHub'a. - Zastąpienie dotychczasowego routera przez mini PC z systemem
OPNsense. - Dodanie awaryjnego zasilania.
Podsumowanie
Ten homelab to efekt dwóch lat nauki przez praktykę. Mimo pewnych kompromisów, udało mi się stworzyć stabilne, bezpieczne i wysoce zautomatyzowane, a co najważniejsze w pełni zrozumiałe dla mnie jako administratora środowisko, które codziennie ułatwia mi pracę nad własnymi projektami. Każdy rozwiązany problem przybliża to środowisko do poziomu profesjonalnej infrastruktury.